
フォントの種類と大きさ次第では、まぁ確かに見分けにくいんですが・・・よくもまぁ校正をパスしたなぁ。正規表現は簡単です。
\P{IsKatakana}リ\P{IsKatakana}
ここでのアイデアは、「『リ』が正しく使用されている場合は、左右どちらかにカタカナが続く必要がある」ということです。つまり両方共カタカナでない箇所を検出すればいいのです。
それほど見分けにくいものではないのに、なぜこんなことが起きるのか正直不思議です。確認せずに一括置換したか、日本語入力システムを持たない海外のエージェントが似ている字形をコピペしたのかなぁ。
すべてのカタカナの 1 文字孤立を検出する正規表現は次のようになります。
[\P{IsKatakana}^]\p{IsKatakana}[\P{IsKatakana}$]
ここで「^」は角かっこの直後にはないので文頭を表します。また、「$」は文末を表します。日本語で説明すると、「カタカナ 1 文字の左側が非カタカナか文頭、かつ右側が非カタカナか文末である」になります。
実際に適用してみましょう。
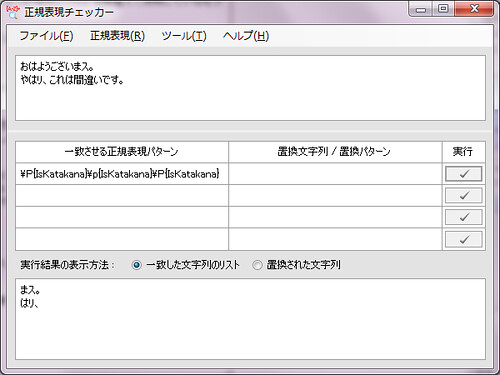
もっと見分けにくいものに、カタカナの「カ」と漢字の「力 (ちから)」があります。この間違いには出会ったことがありません。標準的なフォントでは、校正者も読者もほぼ区別できませんが、最終原稿のフォント次第では、ひどく目立つかもしれません。
カラス (カタカナ)
力ラス (ちから)
人生で出会うことは、ほぼないと思いますw。「カ (カタカナ)」の不適切な使用は上の表現で検出できますが、「力 (ちから)」の不適切な使用を検出したいと思う方は、正規表現の勉強も兼ねて色々と試行錯誤してみてください。私も暇なときに考えておきます (なんて奴だw)。
100% 正確に検出できる正規表現ではなく、正しい用法が少しヒットしても構わないと考える必要があると思いマッスル。
3 件のコメント:
ITや翻訳の話ではなく、前々職だった塾教師時代のことを思い出します。
中学入試の国語でよく出る(今はどうか知りませんけど)漢字の読みの問題。しかも答えはカタカナで書く。
損失。
今度はIT翻訳にからんで。
私が実際に見たことがあるのは、
カタカナの「ニ」と漢数字の「二」。
カタカナの「ヘ」とひらがなの「へ」。
非日本語圏の翻訳ベンダーを経たメモリーでした。
これはやはり、日本語非ネイティブのコピペですかね・・・
コメントを投稿